
Automated Dataset Generation & YOLO Training
YOLO Automated Training
Ein Workflow, der aus einer initial annotierten Aufnahme automatisch variierte Ansichten erzeugt, Bounding Boxes mitführt und daraus ein YOLO-Modell für industrielle Bauteilerkennung trainiert.
Projektüberblick
Von einer Annotation zu einem trainierbaren Datensatz
Statt jedes Bild manuell zu markieren, wird eine saubere Startannotation als Grundlage genutzt. Danach werden neue Ansichten erzeugt, Labels automatisch angepasst und das Ergebnis als YOLO-Datensatz trainiert und validiert.
Eine manuelle Bounding Box definiert das Objekt und den ersten sauberen Trainingsfall.
Abstand, Blickwinkel, Rotation und Objektlage werden automatisch variiert.
Der erzeugte Datensatz wird in Training und Validierung aufgeteilt und trainiert.
Kurven, Predictions und Tests zeigen, ob das Modell robust genug erkennt.
Pipeline
Automatisierung der zeitintensiven Annotation
Der Kern des Projekts ist nicht nur das Training, sondern die Reduktion der manuellen Vorarbeit: ein Objekt wird einmal sauber markiert, danach entstehen viele gelabelte Trainingsbeispiele aus kontrollierten Variationen.
-
01
Startbild erfassen
Eine klare Aufnahme des Bauteils wird als Ausgangspunkt für den Datensatz genutzt.
-
02
Bounding Box setzen
Das Objekt wird einmal manuell annotiert, damit die erste Label-Geometrie stimmt.
-
03
Ansichten erzeugen
Abstand, Winkel, Rotation, Position und Perspektive werden automatisch variiert.
-
04
Labels mitführen
Die Annotation wird passend zu jeder erzeugten Ansicht aktualisiert.
-
05
YOLO trainieren
Trainings- und Validierungsdaten werden erzeugt und das Modell wird trainiert.
-
06
Predictions testen
Das fertige Modell wird auf neue Bilder angewendet und mit Metriken bewertet.

01 / Datenerzeugung
Viele Ansichten aus einer sauberen Objektdefinition
Ziel ist ein schnellerer Weg zu Trainingsdaten: aus einer Startaufnahme entstehen kontrollierte Varianten des gleichen Objekts. Dadurch wird der manuelle Aufwand beim Aufbau eines ersten Detektors deutlich reduziert.
02 / Training Batch
Annotationen bleiben mit den Varianten synchron
Jede erzeugte Ansicht braucht ein korrektes Label. Der Workflow behandelt die Bounding Box nicht als statisches Rechteck, sondern passt sie an die veränderte Objektlage und Perspektive an.
Varianten anzeigen
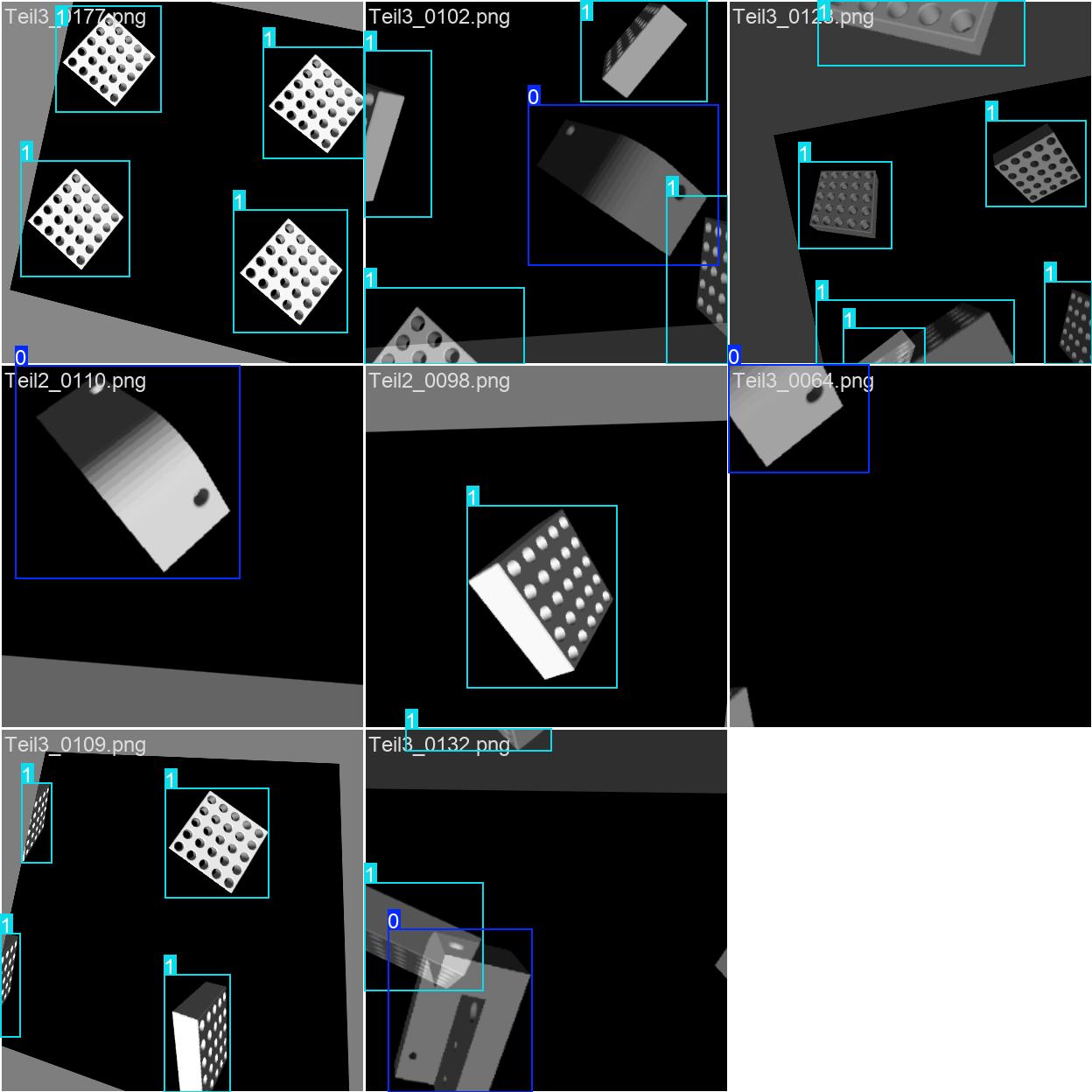
Die Galerie zeigt Beispiele aus Training und Validierung. Entscheidend ist, dass das Modell nicht nur ein einzelnes Bild auswendig lernt, sondern unterschiedliche Lagen, Skalierungen und Ansichten desselben Bauteils sieht.


03 / Modelltraining
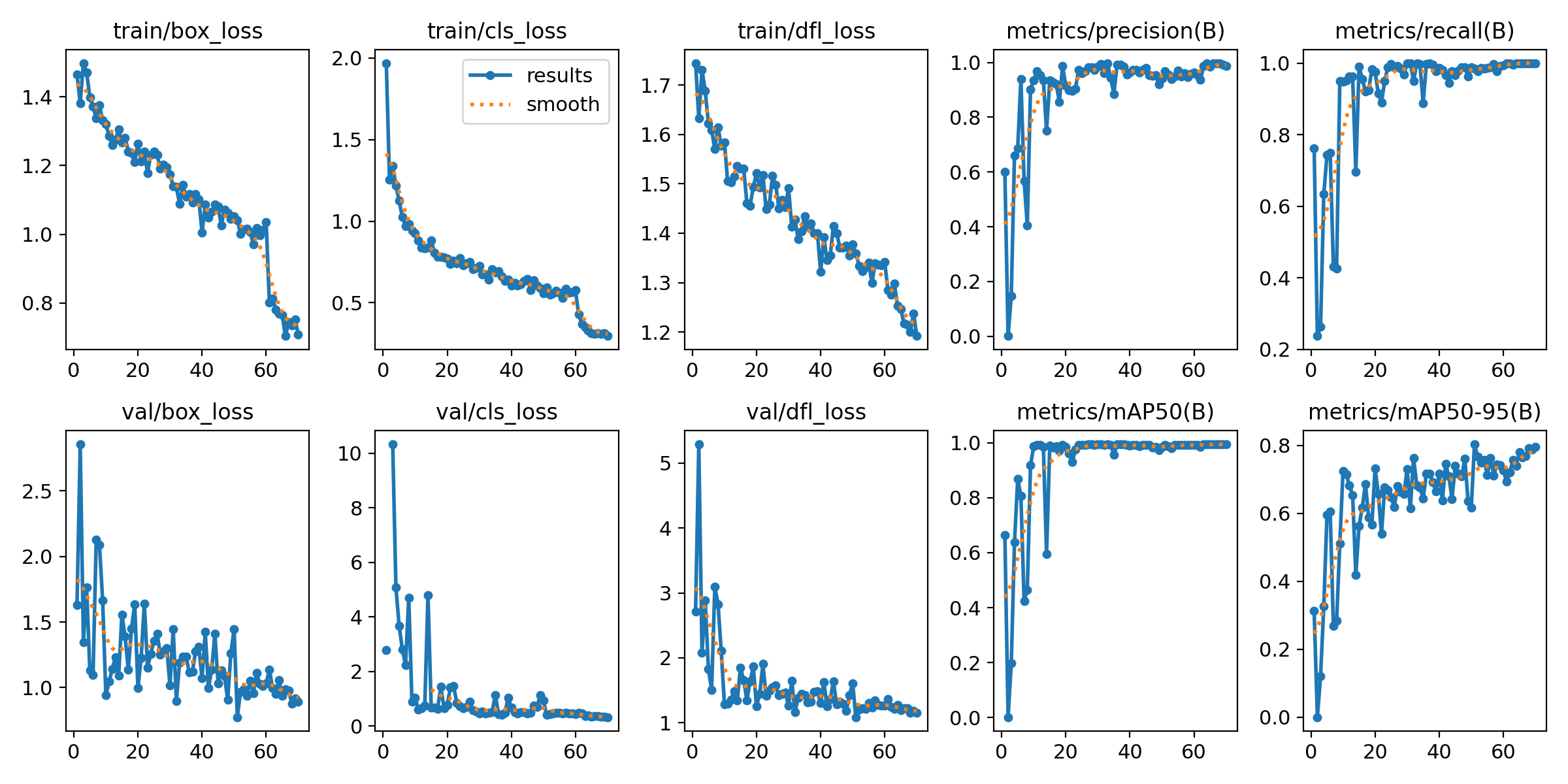
Training, Validierung und Kurvenauswertung
Nach der Datensatzaufbereitung wird das YOLO-Modell trainiert. Die Ergebnisplots zeigen Box-Loss, Klassifikationsverhalten und mAP-Entwicklung und helfen zu erkennen, ob der Datensatz sinnvoll skaliert.
04 / Validierung
Predictions zeigen die praktische Erkennungsqualität
Neben den Metriken sind Vorhersagebilder wichtig, weil sie sofort zeigen, ob die Bounding Boxes stabil sitzen und ob das Modell bei neuen Ansichten die richtige Objektklasse erkennt.
Metriken anzeigen
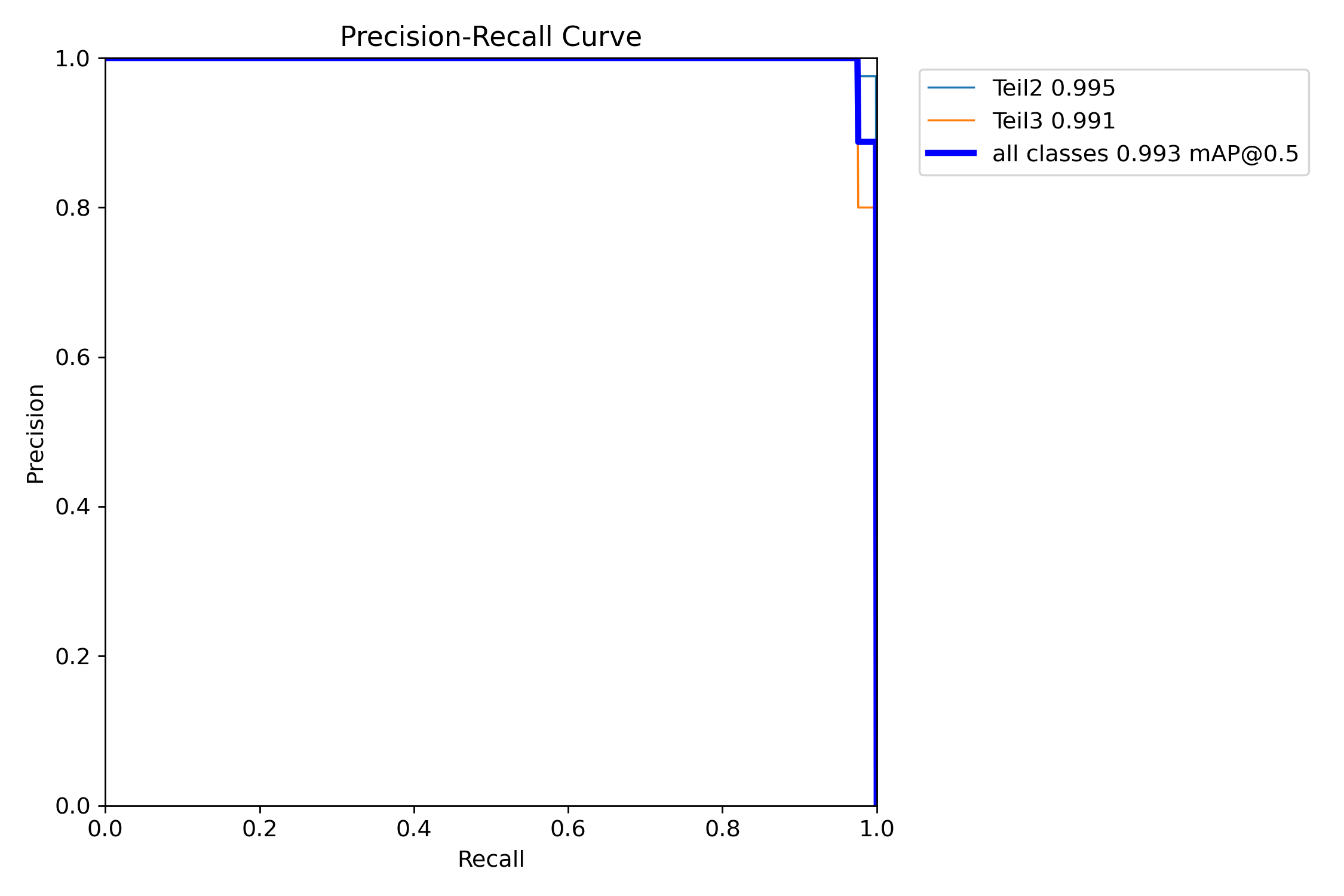
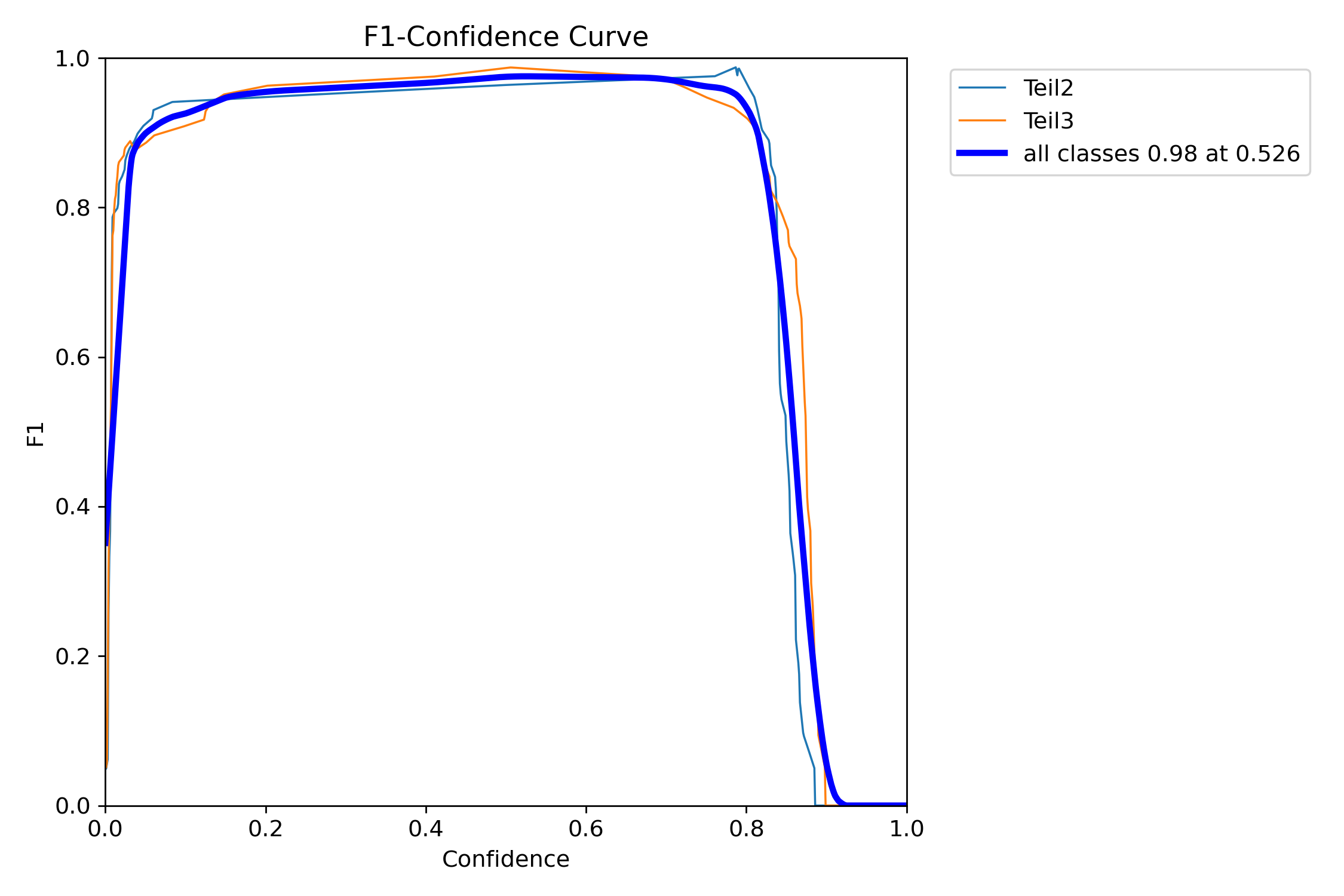
Precision-Recall- und F1-Kurven unterstützen die Entscheidung, ob mehr Varianten, bessere Startannotation oder andere Trainingsparameter notwendig sind.
05 / Ergebnis
Trainiertes Modell als Eingang für weitere Vision-Prozesse
Das trainierte YOLO-Modell kann anschließend in technische Pipelines eingebunden werden, zum Beispiel als ROI- und Klassenschritt vor Pose Estimation, Prüfung oder automatisierter Bauteilerkennung.